
To Appreciate its Limits, Consider ChatGPT as a Word Calculator
In exploring what AIs like GPT is good for, I may or may not have spent too much money on fine-tuning language models... sharing insights from my journey here.


After spending about 8 months and a few thousand dollars renting GPU servers to fine-tune Mai, a marketing-specialized language model, I wanted to share some thoughts on the limits of ChatGPT for marketing.
If you're a marketer, business owner, or entrepreneur, this is written to help you get a better grasp of how Language Models like ChatGPT work. It will also help you know when & where to use them in your work.
We'll cover the following topics in this order:
An intuitive view of how Language Models like GPT work under the hood, without getting into mathematical details.
How certain mechanisms within GPT lead to its limitations and inconsistencies
How these challenges can be addressed with updated workflows
The Analogy of a Word Calculator
To help you understand how models work, let's distill the concept of a model into 3 phases:
There's input
There are operations on an input
And it produces an output
Just like with a calculator:
There's a set of inputs (the numbers)
There are operations on those inputs (addition, subtraction, etc)
And there is an output (another set of numbers)
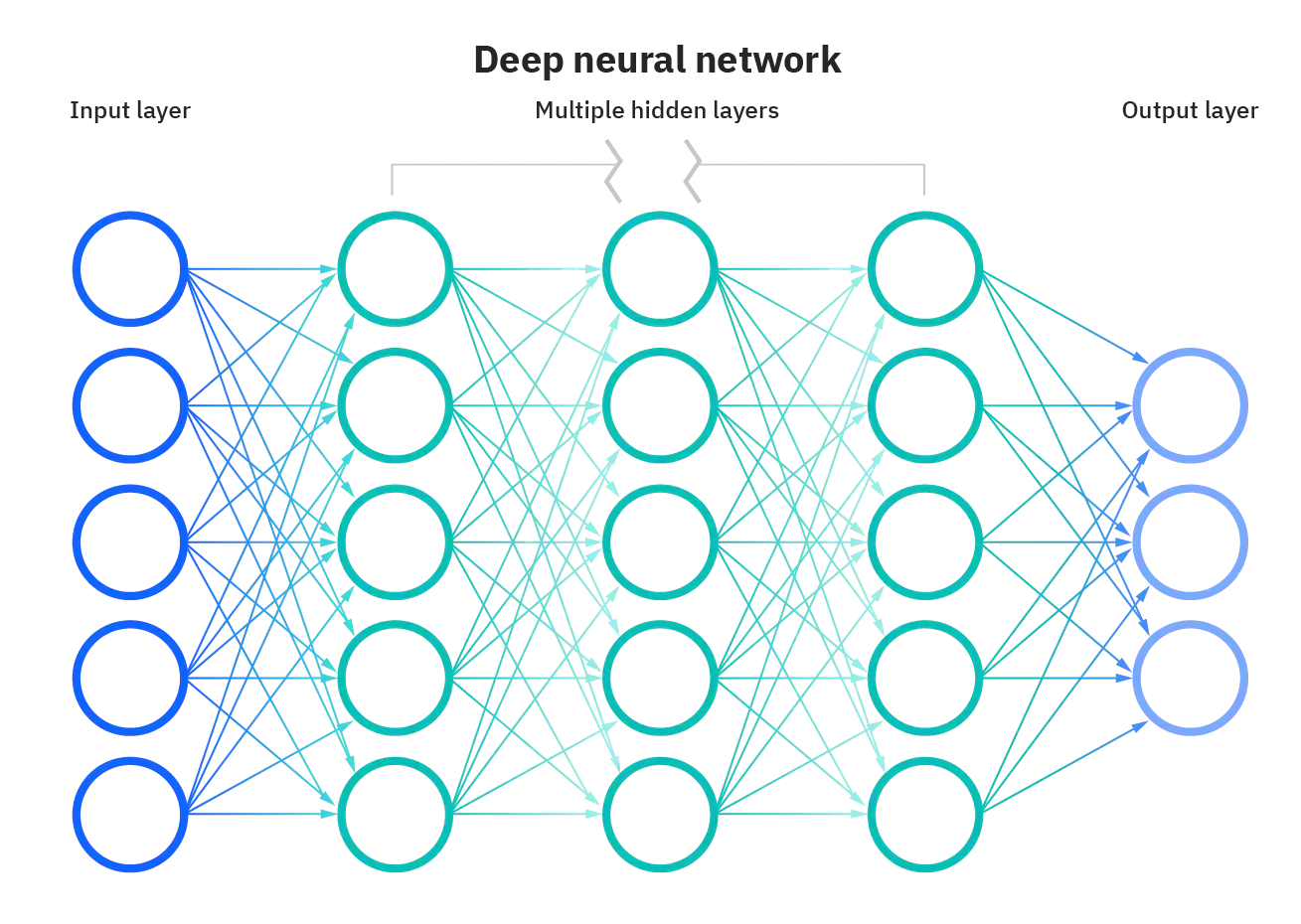
Below, you'll see how a neural network architecture generally looks like.
Don't be intimidated. You just need to know that there's an input, an output, and the things that happen in between to produce the output, which are called "hidden layers." Just think of it as slightly more complex mathematical operations that turn an input to an output.
Now let's look at the Transformer Architecture, which is the basis of models like GPT. I blurred out the technical parts so you don't freak out. You don't need to know them if you're non-technical. We'll walk you through a quick tour of how an input set of words produces an output set of words in a bit.

Cool, so it takes an input of words, does some calculations, then it produces an output of words. So how does it do that?
At its core, Language Models like GPT-3 are "word calculators".
Here's how it works at a high level:
It takes your input of words and changes it into digits or numbers.
It needs to be converted into numbers so we can do math operations.
It uses a "word-to-number" dictionary for converting it. It's called tokenization. GPT3 has a dictionary or token vocabulary size of 25,000.
It then takes these digits and performs a series of mathematical operations. The number of mathematical operations is extensive. GPT has 175 billion parameters.
What is a "parameter"?
If we take a simple formula, such as y = x + b, and let's imagine that x is your input word and y is the output word, b is just 1 parameter. Obviously, if you use this weak formula, our embryo GPT here won't work.
But this explanation of how a "1 parameter model" looks like will help you appreciate the sheer size and scale of how a 175 billion parameter model would look like, and why it requires huge GPU clusters to work.
Once our operations are done with the computation, we are given another set of digits. These digits are then converted back to words using our 25,000 sized "word-to-number" dictionary.
That's why language models can do reasonably well in certain translation tasks, as its true lingua franca are numbers, and words & syllables are mere numbers in the eyes of the language model.
Once it gets converted, one thing about the Transformer architecture is that it produces "output probabilities", which contain a set of words with a probability attached to them.
For example, here's how the output probability would look if I used the input phrase "Life is like a box of...?"

Using its token dictionary, a digit was associated with "Ch", and it was likely correct with a 75.40% probability. This quote shows up so often that other similar characters are likely to show up as well. The slash-n thing is just a "new line" (so the other option it considered was adding another line to the text).
So now you might be thinking: "Ok thanks Kenn, you're such a nerd. Now what?"
Well, now that I have given you an easy and simple mental model on how GPT works, let me tell you its problems, and how it applies to your work.
Ready?
Problem 1: Instruction Fine-Tuning Influences the Calculations from Input to Output
ChatGPT is not an expert, and you shouldn't rely on it for deeply technical work.
Let's continue with our word calculator analogy to understand why.
The difference between our fancy word calculator and a regular calculator is that Machine Learning Practitioners can teach this model tasks or patterns through a process called "Instruction Fine-tuning". This is one of ChatGPT's innovations.
Big word, but let's break down "Instruction Fine-tuning":
It takes canned instructions as input and canned responses as output
AI researchers fed these instruction-response pairs to fine-tune the model
"Fine-tuning" means it "tunes" the parameters / calculations between the input and output so it's more likely to produce the canned response for the given instruction
Let me share an example:
Let's say you want to teach the language model to be polite for a given "angry" instruction
You can create 500 angry prompts or inputs, with 500 polite responses or outputs to the said inputs.
This "fine-tuning" process changes the calculations within the model to make it more polite.
This instruction fine-tuning process helped companies like OpenAI, Anthropic, and more with "model alignment". There is more to alignment than this, but let's stick to this fine-tuning concept for now.
Given this process, GPT was trained through an army of contractors to do the following tasks (this is from the InstructGPT paper):

The main challenge with this process is that Language Models can be heavily influenced by the annotators. Therefore, its expertise level is calibrated according to the level of its annotators (which are generally 25 year old freelancers).
The bottom line here is that while ChatGPT is strong at giving you the first draft, or sharing introductory concepts, it's not to be relied upon when you get very technical on a subject.
While benchmark results are quite impressive, there are limitations to situations that don't show up in a test. This leads me to the next point.
Problem 2: As language models calculate the most likely word, you get output people will most likely say based on the fine-tuning data
The major challenge with consumer-focused products such as ChatGPT is that it aligns with what is acceptable for the average person.
For instance, when I first used ChatGPT, I strongly disliked its writing style. Here's how a generic ChatGPT output would look (exaggerated a bit to show its commonly used words).
Are you tired of [product_name]? Are you struggling with [problem]? Are you looking for [solution]? Say goodbye to [problem] and hello to [benefit]. Join the ranks of [audience] and elevate your game by trying out the ultimate in [benefit]: [product_name].Pretty terrible. Nevertheless, I don't blame it, as it's trained on contractors from Upwork and Scale AI, which aren't necessarily considered experts. Let's put it this way: no expert would want to be hired as a freelance annotator. They have better things to do.
Snippet from the InstructGPT paper:

Furthermore, given that the outputs are probabilistic, there is a non-zero chance of sharing wrong information. That's simply due to the nature of the neural network architecture shared above, where it produces output probabilities. And further, its calculations are influenced by the army of contractors who annotated the data, so it's skewed to reflect thoughts from the perspective of a junior hire.
What are the implications of this annotator background? The point here is that:
If you're using ChatGPT for assistant-related tasks such as drafting an email, automating data extraction, or summarizing a piece of text, it is the right tool for the job.
But if you're doing it for research, academic work, or programming, be aware that its skill level is likely similar to its annotator background (likely junior level, prefers contractual work than long-term employment), then you'll have a better appreciation of its limits.
Given these 2 major challenges, what can be done?
Solution 1: Bring your own expert data, or leverage specialized AI
The major point shared was that the quality of fine-tuning data matters a lot. For the InstructGPT paper, they used 13,000 instruction-response examples (and another 64,000 to align GPT to certain values).
The InstructGPT paper was published in Q1 2022, and there has been progress since then:
Databricks has an open-source 15k dataset that replicates instruction-response examples, annotated by their own employees.
The LongForm dataset is a 25k dataset based on publicly available data.
The LIMA dataset proposes that you only need 1000 instruction-response examples.
And the Self-Align proposes only 300 human annotations, which replace the 64,000 examples OpenAI used to align the model with values & principles.
Therefore, if you want to create a specialized, fine-tuned AI for your specific use cases, you'd have to collect about 300-15K data points for it to adjust to what you want. This still assumes that you need a foundation model like GPT, Anthropic, or PaLM as you need that as a foundation. I don't recommend training your own model as the going price for that is at least at least $450,000. But the difference here is that you can add an "expert touch" to your model if you have the right dataset.
If you don't have the resources or time to construct such a dataset, it's wise to leverage existing AI solutions that use a specialized dataset.
For instance, Mai is based on similar principles. We used an expert-annotated dataset (tens of thousands of marketing examples), and fine-tuned it on a foundation language model. We currently have custom Mai language models built on top of GPT, Cohere, and a few others. We use those to produce higher quality output and higher converting copies than ChatGPT would give.
We currently use Mai for our performance marketing agency. We've seen productivity shoot up to the point that we're considering a permanent increase in capacity (i.e. more clients per manager) with a concurrent increase in manager salaries (while improving company profit margins).
While there is an upfront cost to developing your own language model, if it comes paired with the right organization structure improvements, it pays out after 1 year.
Solution 2: Unique outputs come from combinations of your dataset's instructions
You may have tried some of the "prompting tricks" for ChatGPT and others, but it invariably fails in some specialized prompts, as we've noticed quite often.
For instance, if we laid out some marketing principles, here are some:
ChatGPT doesn't know the marketing principle of "value reframing"
It doesn't know "identification".
No idea about "contrast".
And it's pretty weak with "associations" and "problem agitation"
Our method to solve this is to construct our own instruction-response dataset that demonstrates to the model how "value reframing", "identification", "contrast", and "associations" are written.
By sharing these expert-labeled examples (which are in the order of hundreds each), the model then learns how to actually write it out.
No other AI provider currently does this.
And the benefit of doing this is that we can get our customized model to produce more unique outputs, as it's now armed with the marketing principles we've taught it to use.
And the key to allowing the model to do this is by feeding it with a specialized, expert-annotated dataset, which is what we've done.
Bullet Point Insights
Let's break down what you've read in this article:
All neural networks are models comprised of 3 things: inputs, outputs, and calculations
GPT is a transformer neural network that 'transforms' an input sequence of words into an output sequence of words, through a series of calculations.
To train the base GPT to respond to instructions, it is fed with 13K+ input-output examples, written by human annotators from Upwork & Scale AI. This modifies how calculations are done, creating outputs that make sense to humans. This process (and RHLF, which is out of scope for this article) has produced ChatGPT.
However, this set of instructions is biased towards what an average person or someone with the Upwork / Scale AI profile would prefer. This means that ChatGPT is suitable for tasks that you'd give to a person on Upwork, but it's not effective for tasks that you'd delegate to an expert.
That said, given that the premise of this process is reliant on the dataset, if you used experts to construct the dataset, you'd get more expert-level output.
Expert annotation (in the marketing sense) is what we've done with Mai, which allows us to offer above standard output for our customers. Mai is built by Monolith Growth Consulting, a performance marketing agency.
Conversely, you can do the same for your organization, provided you have a clear use case to optimize for, and a team ready to construct the dataset. If you don't, it's better to leverage existing AI, such as Mai for various marketing tasks.
You can create a more distinct set of outputs from your specialized AI, provided that a) you have an equal distribution of your input-output types and b) you can hard code specific principles or prompt phrases that will help steer your AI in the right direction.
With the right organization restructure, you can improve your company's operational expense and hence profit margin with specialized AI.
With that in mind, you may consider the following possible steps.
Your Next Steps
Given all of what's shared in this article, you have a few paths to consider:
Realize that your use case is mostly in the "simple assistant" camp, where you need to only summarize data or do data extraction, then ChatGPT is for you.
Understand that you need better results from AI outputs, so you may need to consider a specialized AI trained on an expert-annotated dataset. If your use case is marketing, I encourage you to look at Mai.
If you're keen to explore how AI can help you increase your profit margins in a meaningful way with some restructuring (in our case, it's about a 30% improvement from our estimate), then feel free to have an exploratory chat with me here. We can help you explore your options to train your own specialized model. You'll need at least $1,000,000 per year in revenue for a project like this to pay out.
Key points and ideas of this article was written by Kenn. Draft made by a developer version of Mai, a Generative AI writer. Help your customers better & accelerate your marketing productivity using Mai. Free plan available:
https://www.maiwriter.com/
Author Background: Kenn Costales is the Founder of Monolith Growth Ventures. Brands include Monolith Growth Consulting, a performance marketing agency, and Mai, a generative ai software for in-house marketing teams & agencies. Forbes 30 Under 30 2019.